本文为 The Design of a Practical System for Fault-Tolerant Virtual Machines 1的阅读笔记总结,涵盖了 MIT 6.824 Lecture 42 的部分总结内容。
1. Introduction
本论文设计了一种虚拟机容错机制,主要以主从备份的方式实现,备份 VM 和主 VM 几乎实时保持一致,这样才能保证不暴露错误给客户端,能在主 VM 发生故障时继续上线服务,解决 fail-stop failure(例如电源、网络、硬件等问题,以及相同机器的其它软件造成的 kernal panic 或 reboot),做到不丢失数据。
软件本身 bug 或者硬件缺陷不能通过副本的机制来解决,例如在软件 bug 上,如果 mapreduce 的 master 有主从节点,可能在两个节点上由于 bug 的计算错误导致主从节点都产生了错误结果。
不同于以往分布式容灾系统采用机器级别的副本复制(复制 CPU 寄存器、内存和 IO 设备),本论文提出的 VM-FT 使用副本状态机并执行确定性 replay 操作来将主 VM 的操作同步到副本 VM 上,实现了细粒度的同步,降低了以往方法的高带宽需求。
2. Basic FT Design
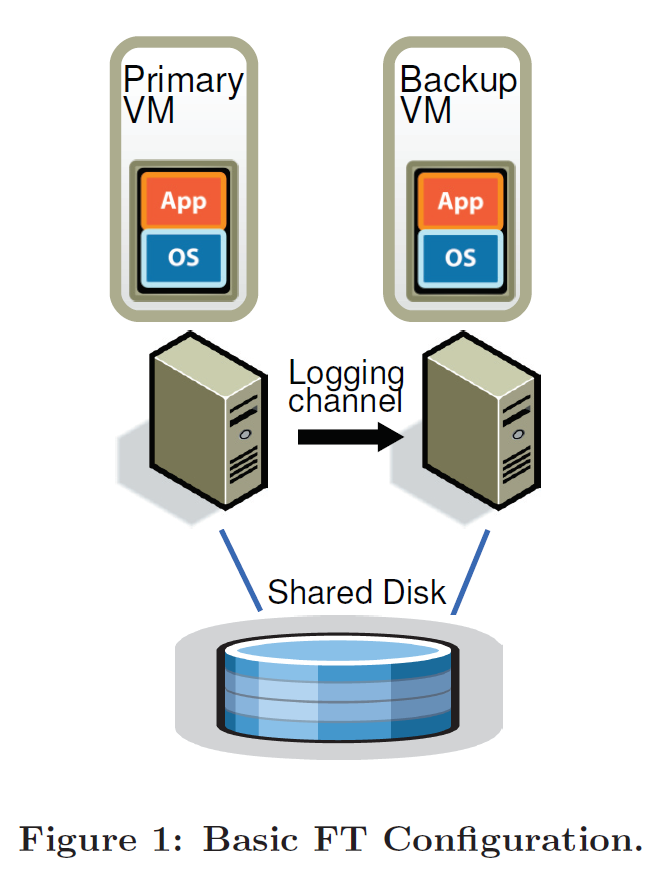
下图是本文设计的容错的 VM 的基本架构,主 VM 和副本 VM 都运行在不同物理宿主机上,两者共享磁盘。仅有主 VM 暴露给外部,接受网络请求以及键盘鼠标等输入。
主 VM 将其所有输入通过 logging channel 的网络连接发送给副本 VM,副本 VM 将执行同样的操作以保证两者处于相同状态。为保证状态一致,本文为主 VM 和副本 VM 设计了特定的协议。
另外,主 VM 和副本 VM 是否出现故障问题,是通过系统的心跳包机制和监测 logging channel 上的流量信息来实现的。当出现故障问题或者是发生网络分区导致的脑裂现象,要保证仅能有一个VM 接管问题 VM ,继续为外部服务。
2.1 Deterministic Replay Implementation
如果两个确定性的状态机在相同初始状态且接受相同顺序的输入,那么这两个状态机会产生相同的输出结果。基于这一点,副本虚拟机服务器可以被当做是状态机的副本。一个虚拟机有一系列输入(网路包、磁盘读取、键盘和鼠标输入)、以及一些非确定性事件(例如虚拟机的中断)和非确定性操作(读处理器的时钟周期计数器),这给对虚拟机的副本执行带来了以下挑战:
- 要准确的所有的输入和必要的非确定性事件,以保证副本 VM 的操作和主 VM 一致
- 准确在副本上执行以上操作
- 副本的 Replay 操作不能阻碍 VM 性能
- X86 架构处理器有很多未定义的事件,存在副作用
VMware deterministic replay 将主虚拟机的输入和可能的非确定性操作以日志项的形式写到发送到副本虚拟机,这使得副本虚拟机能够执行 replay。对于非确定性事件(例如定时器和 I/O 完成中断),能在这些事件对应的指令上进行实时记录,这一部分事件的记录,VMware deterministic replay 利用了 AMD 和 Intel 中的性能计数寄存器来实现。
另外,日志项中包含了以下内容:
- 事件发生时的指令号
- 事件类型,网络输入或者是其它指令
- 数据,如果是不确定指令,则该数据时副本 VM 中的执行结果,这样使得不确定性事件能在主 VM 和副本 VM 上结果保持一致
2.2 FT Protocol
通过确定性重放操作,副本 VM 能够从 logging chanel 中读取主 VM 的各种操作,并实时在副本 VM 中执行类似操作。为了实现日志项的容错能力,本节定义了容错协议,主要是 Output Requirement 和 Output Rule。
Output Requirement:如果主 VM 发生故障后副本 VM 接管后,副本 VM 必须接管原来主 VM 已经完成或部分完成的工作,对外界的输出要保持一致。 即 failover 期间,上述操作对客户端是透明的,客户端不会被中断服务或者是察觉到不一致。
可能出现的一种问题是,logging channel 中还有较多的日志项,副本 VM 来不及 replay 这些操作,如果要等到 replay 完所有的日志项,才能继续上线完成 failover,这势必会造成客户端被中断服务。另外,还有一种更严重的情况,即如果主 VM 在产生输出后发生故障宕机了,副本 VM 在 replay 完成后接管,当可能会被不确定性的事件影响(例如计时器中断),这样可能导致执行路径改变,副本 VM 和主 VM 的状态不一致。为解决上述问题,本论文提出了 output rule。
Output Rule:如果主 VM 欲产生到客户端的输出,其必须延迟这项输出操作,直到主 VM 收到来自于副本 VM 的关于该输出的确认日志项。 流程如下图所示:
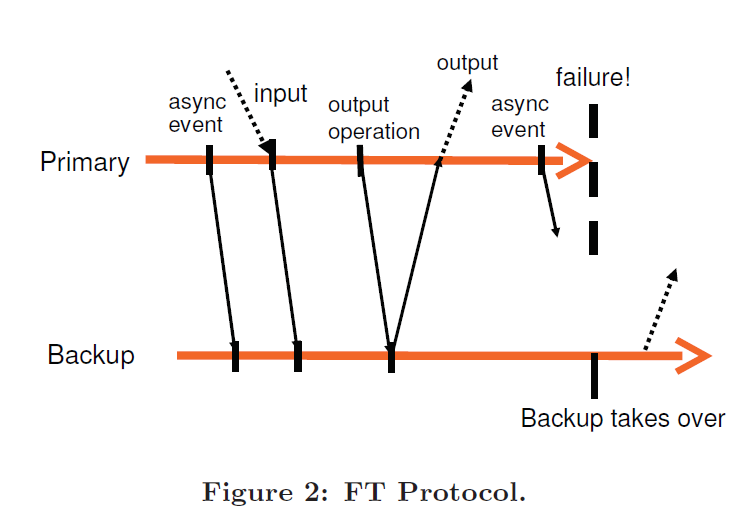
此外,采用 ouput rule 的主 VM 不会停止执行并等待 ACK,其仅仅推迟对外部的输出,同时又由于 OS 支持的非阻塞磁盘和网络输出,主 VM 继续能执行其它程序的情况下异步完成输出操作。
对于外部输出,我们并不能保证副本 VM 在上线后接着主 VM 在故障前的部分输出后继续输出,难免可能会存在某些网络包丢失或者重复的情况,对于这种情况,本论文使用了一定的网络基础设施(包括 TCP)、OS和应用程序来协助解决,在这些层次均会进行一定的写操作以补偿丢包。
2.3 Detecting and Responding to Failure
故障后的操作:
- 如果副本 VM 发生故障,则主 VM 停止向 logging channel 中写日志项,继续正常执行。
- 如果主 VM 发生故障,副本 VM 执行完 replay 后,被提升为新的主 VM,上线并为客户端提供服务。此外,在副本 VM 提升为主 VM 过程中,其需要进行一些和设备相关的操作,例如会在其网络中广播现在的主 VM 的 MAC 地址,以及重新发起某些磁盘IO。
故障检测的方式:
- UDP 心跳包
- 检测 logging channel 的流量和副本 VM 发送至主 VM 的 ACK。
如果心跳和流量停止时间超过了设定的超时时间,则会被判断为发生故障。
脑裂问题的解决:
如果副本 VM 停止收到心跳、或者发生网络分区后,主 VM 和副本 VM 都认为对方发生故障,此时 主 VM 和副本 VM 都上线为客户端提供服务,造成脑裂问题。为解决该问题,必须要确保发生以上故障时,主 VM 和副本 VM 仅能有一个上线提供服务,本论文使用了虚拟磁盘的共享存储来解决问题,在共享存储上执行 atomic test-and-set 操作:
- 如果成功,则该 VM 上线服务
- 如果失败,表示已经有 VM 上线服务了,因此当前 VM 不会上线。
- 如果当前操作的 VM 无法访问共享存储,则其一直重试。
如果共享存储无法访问,由于 主 VM 和副本 VM 都共享该存储,则意味着此时 VM 也无法工作。因此,使用共享存储解决脑裂问题不会引入额外的不可用。
故障后的新副本:
如果发生故障后,VM-FT 会通过在其它宿主机上新启动一个备用 VM 作为新的副本,以保证可用性。
3. Practical Implementation of FT
以上章节描述的 VM-FT 的基本设计和协议,本章在此基础上针对 VM 的其它组成部分进行设计和实现,保证系统具有可用性、健壮性以及自动恢复。
3.1 Starting and Restating FT VMs
故障后需要在新的宿主物理机上建立新副本,恢复冗余,以保证容错。当新副本的建立不能妨碍当前主 VM 的执行。因此, VM vSphere 建立一个集群服务,以支持副本的冗余重建,且不带来较大的开销,副本迁移的操作成为 VMotion,VMotion 的步骤为:
- 选择一个宿主机,将主 VM clone 至宿主机上。其中,新的宿主机的选择是由集群服务基于资源使用情况和其它限制条件来确定的。
- 在当前主 VM 和新副本 VM 上设置好 logging channel,并使主 VM 进入写日志模式,副本 VM 进入 replay 模式。
以上冗余重建过程通常在故障后数分钟内完成,且不会对主 VM 产生任何明显中断。
3.2 Managing the Logging Channel
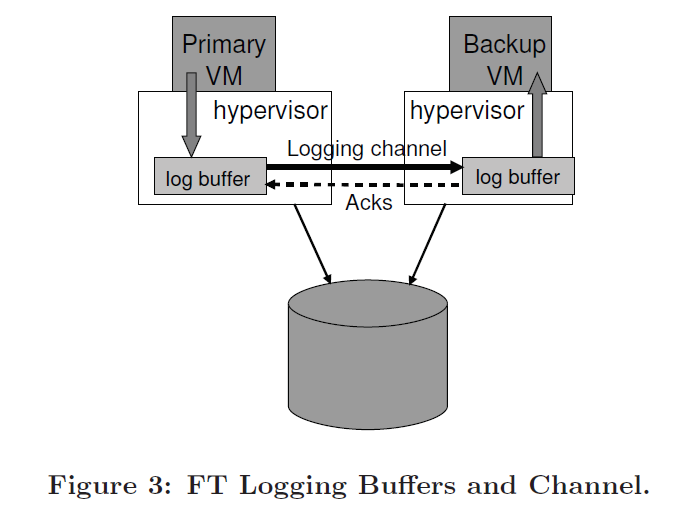
HyperVisor 为主 VM 和副本 VM 分别维护了 log buffer,其通过 logging channel 传递日志项,以生产者消费者模式来组织日志。如下图所示。
- 如果副本 VM 的 log buffer 读空了,其停止执行,直至收到收到新的日志项。
- 如果主 VM 的 log buffer 写满了,则会减慢主 VM 的执行。当时在此时,可能会出现客户端无法收到主 VM 的回应。
- 出现主 VM 的 log buffer 写满的情况可能如下:副本 VM 执行速度过慢,造成消耗日志慢。 —-> 这种情况很有可能是由于物理宿主机上可能还有虚拟机实例,造成副本 VM 所得到的 CPU 和内存资源不足而造成的。
- 如果副本 VM 执行速度过慢,那么主 VM 出现故障后,failover 的时间等于错误检测时间加上 副本replay 所有日志项的时间。如果 failover 时间过长,很有可能导致服务不可用。
因此,主 VM 和副本 VM 的执行速度基本要一致。在本论文中的协议中,其日志项包含了主 VM 和副本 VM 之间的执行延时时间,如果执行延迟时间过长,则 VMware FT 分配给主 VM 的 CPU 时间片减少。这一实现使用了 feedback loop,依据执行延迟时间来动态分配 CPU 资源。 (论文中有提及这种情况较为罕见)
3.3 Operation on FT VMs
对于大部分特殊操作,例如关机、CPU 份额的变动,这些都应该通过 logging channel 传送到副本 VM 上去。但是 VMotion 操作不能,因为 VMotion 操作适用于建立冗余副本的。相关细节如下:
- 主 VM 的 VMotion 操作比常规 Vmtion 操作更为复杂,因为副本 VM 需要断开和主 VM 的连接,在合适的时间重新连接到新的 主 VM 上。
- 普通的 Vmtion 操作,必须保证所有的磁盘 IO 完成,此时。
- 主 VM 能快速知道其磁盘 IO 已经完成。
- 副本 VM 进行 VMotion 时,难以知晓主 VM 的所有 IO 操作是否已经完成。因为副本 VM 必须重放主 VM的执行操作,在同样的执行点完成 IO。对于这一问题,VMware FT 是这样解决的:当主 VM 完成其最后的 IO 操作,主 VM 会发送一个日志项表明其已经完成所有 IO 操作,这样副本 VM 收到该日志项时,其能在特定的执行点知晓所有 IO 操作均完成,可以开始进行 VMotion 操作。
3.4 Implementation Issues for Disk IOs
磁盘 IO 相关的问题及解决办法分别如下:
- 非阻塞的磁盘 IO 在并行执行下,多个任务可能会访问同一磁盘位置,导致不确定时间的产生;另外,本论文实现的磁盘 IO 由 DMA 送入内存中,并发的磁盘操作可能导致在访问同一内存页时,产生不确定事件。对此本文的解决方法是,探测这种很少发生的 IO 冲突,强迫冲突磁盘操作在 主VM 和 副本 VM 上使用顺序执行。
- 物理机 NIC 收到数据包时,不能直接递送给主 VM,因为无法确定数据包复制到 主 VM 内存的确切时间,在特定的事件差异内,可能主 VM 读到了 DMA 之前的数据,副本 VM 读到了 DMA 之后的数据。对此本文的解决方法是采用 bounce buffer,过程如下:物理机 NIC 首先将数据包发送给 VMM ,然后网卡产生中断至 VMM 提示数据包已到达,然后 VMM 暂停主VM,并记录主 VM 正在执行的指令,将整个数据包复制到主 VM,并模拟 NIC 网卡中断进入主 VM,然后将数据包和指令号通过 logging channel 发送给副本 VM。
- 主 VM 上正在进行磁盘 IO 时发生故障,此时副本 VM 上线接管,当此时新提升的主 VM 并不知道磁盘 IO 是否完全完成,而且之前副本 VM 的 IO 操作并不是由外界显示发起的,这导致了新提升的主 VM 亦没有显示的 IO 完成提示。这会使得虚拟机操作系统类触发一个 abort 或者 reset。对此,新提升的主 VM 会重新发起 IO,因为此时的冲突已经消除,在 VM 中这是幂等的操作。
3.5 Implementation Issues for Network IOs
对于某些优化操作,hypervisor 异步更新 VM 网络设备的状态,但异步更新无疑给 VM 的状态增加了不确定性。因此,本论文把异步更新 VM 环缓冲区操作修改为 hypervisor 的陷入操作来处理。在此之上,本文还做了如下两方面的优化:
- 将数据包分组。收到一组数据包后再触发陷入操作,避免了多次陷入操作带来的额外开销。
- 减少数据包传输延迟。本文通过减少线程上下文切换来达到,当收到 TCP 数据时,hypervisor 允许函数注册到 TCP stack,随后在延迟执行上下文中被调用。
4. Design Alternatives
4.1 Shared vs. Non-Shared
上文中讨论的 FT 机制使用了共享磁盘,仅有主 VM 会写入磁盘,且该写操作会推迟到满足 Output Rule 后。
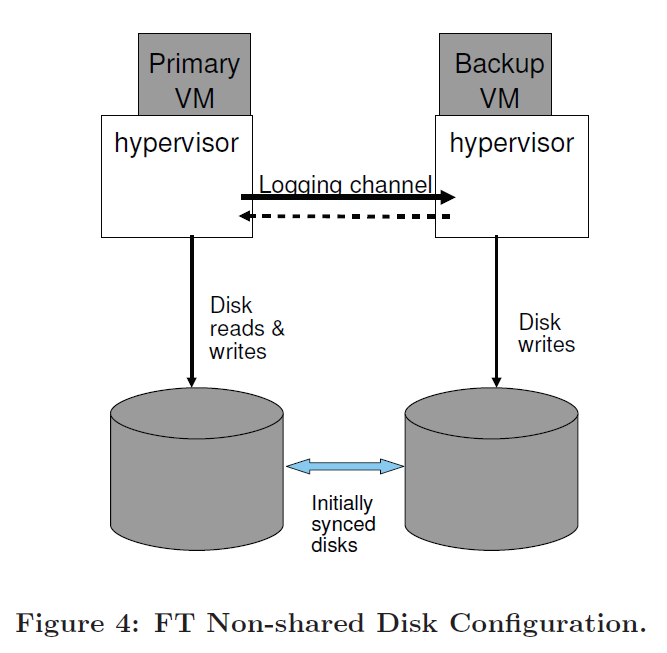
本节介绍了无共享磁盘的设计,如下图,在该情况下,主 VM 和副本 VM 的虚拟磁盘内容会保持一致,此时,磁盘会被 VM 视为独占资源,因为在写操作时不需要满足 Output Rule 。该设计具有如下特点:
- 能解决共享方案的主 VM 和 副本 VM 无法访问共享存储的问题。例如:共享存储不可用、主副 VM 的距离较远等情况。
- 不共享方案的主副 VM 的磁盘必须保持同步。当副本 VM 失败重启后需要显示的重新同步,另外,在进行 VMotion 操作时,不仅要考虑运行状态,也需要考虑磁盘状态。
- 不共享方案需要引入一些外部方法来决绝脑裂问题。例如引入两个服务器都能通信的第三方服务器。
4.2 Executing Disk Reads on the Backup VM
两种方法的副本 VM 从不读其虚拟磁盘,其均从 logging channel 中读。本节提出了一种方案时副本 VM 不读 logging channel,而是从磁盘读。该设计的特点如下:
- 减轻了 logging chanel 的负载。
- 可能会减缓备用 VM 的执行速度,因为备用 VM 在执行时需要等待磁盘读操作。
- 如果读磁盘发生问题,主 VM 读成功后,则副本 VM 需要一致读,直至成功,因为其需要和主 VM 保持一样的数据。反之,如果主 VM 读操作失败,则其读失败的日志应该随 logging channel 发送至副本 VM ,且副本 VM 也保持失败状态。
另外,如果共享方案中进行磁盘读操作时,要注意这种情况:如果主 VM 读了一区域后马上对该区域进行写操作,那么该磁盘写操作必须延迟到副本 VM 执行磁盘读后,否则副本 VM 可能会读到错误数据。
Summary
VM-FT 采用副本状态机的方式,根据一定协议在副本上执行确定的 replay 操作,为计算服务提供容错性,实现了异地容灾。论文中还有一些小细节:本文论文的虚拟机容错协议(论文发表于 2010 年)仅支持在单核心处理器的 CPU,不能支持多核心处理器,随着网络基础设施的发展,后续 VMware 通过机器级别的副本(复制内存和寄存器的所有内容)实现了多核心处理器的容错。另外,本文论文中的共享虚拟磁盘,文中并未提及其容错方法,可能存在发生单点故障的可能性。
Refernence
-
The Design of a Practical System for Fault-Tolerant Virtual Machines ↩︎
-
https://www.youtube.com/watch?v=M_teob23ZzY “MIT 6.824 Lecture 4 Primary-Backup Replicatipon” ↩︎