本文为 The Google File System1 的阅读笔记,主要为论文前五章,涵盖了 GFS 在并行性能、副本复制、一致性、容错等方面的设计思想和细节。
Abstruction
GFS 文件系统是一个面向数据密集型的可扩展的分布式文件系统,能运行在廉价机器上,且具备容错能力,能提供高性能服务。GFS 的设计参考了传统分布式文件系统,但 Google 基于分布式文件系统在企业内部的业务需求重新进行了设计。
1. Introduction
GFS 的设计目标是性能、可伸缩性、可靠性以及可用性。设计思路如下:
- 组件失效是常态事件,而不是意外事件。GFS 在廉价机器上易受到各式各样的问题导致某些组件无法正常工作,例如程序bug、操作系统bug以及底层硬件bug,因此,GFS 系统在设计时将持续监测、错误侦测、容错能力、自动恢复等机制整合到系统中。
- 文件尺寸大。如何管理大尺寸文件,GFS 设计时重新考虑了 I/O 操作优化以及文件块尺寸。
- 大部分写操作都是在尾部追加数据。针对数据的操作大都为顺序读和顺序写,很少有随机写操作。数据的访问几乎不会出现"热点问题",即频繁访问特定数据,因此缓存作用不大,因此,GFS 需对追加写进行性能优化,和保证写操作的原子性。
- 在引用程序和 API 设计方面增加了整个系统的灵活性。减缓了 GFS 对一致性模型的要求,简化了设计。
2. Design Overview
2.1 Assumptions
Google 根据其实际业务需求,对 GFS 的设计列出了相关需求:
- 系统由廉价机器上组成,组件失效常态化。系统循必须持续监控自身状态,做到快速恢复。
- 存储大量大尺寸文件,需要有效管理大尺寸文件。
- 读负载:大规模的流式读取、小规模的随机读取。如果需要优化随机读取,可以将多个随机读取合并排序,转换成顺序批量读取,减少磁盘随机读取带来的延时。
- 写负载:大规模顺序追加写。文件写入后,很少被修改。针对小规模的随机写,系统效率可能不高。
- 明确定义多个客户端并行追加操作到同一文件的语义。实现原子化的多路追加数据。
- 高吞吐量 » 低延迟。大多数任务以大规模批处理,因此高吞吐量为首要设计目标,而很少有程序对单一的读写操作有相应时间要求。
2.2 Interface
GFS 基于上述需求,设计了以下非 Posix 标准的 API 接口:
- 文件以分层目录的形式组织,用路径名标识
- 创建新文件、删除文件、打开文件、关闭文件、读写文件
- 快照操作
- 记录追加操作:保证了多路写操作的原子性
2.3 Architecture
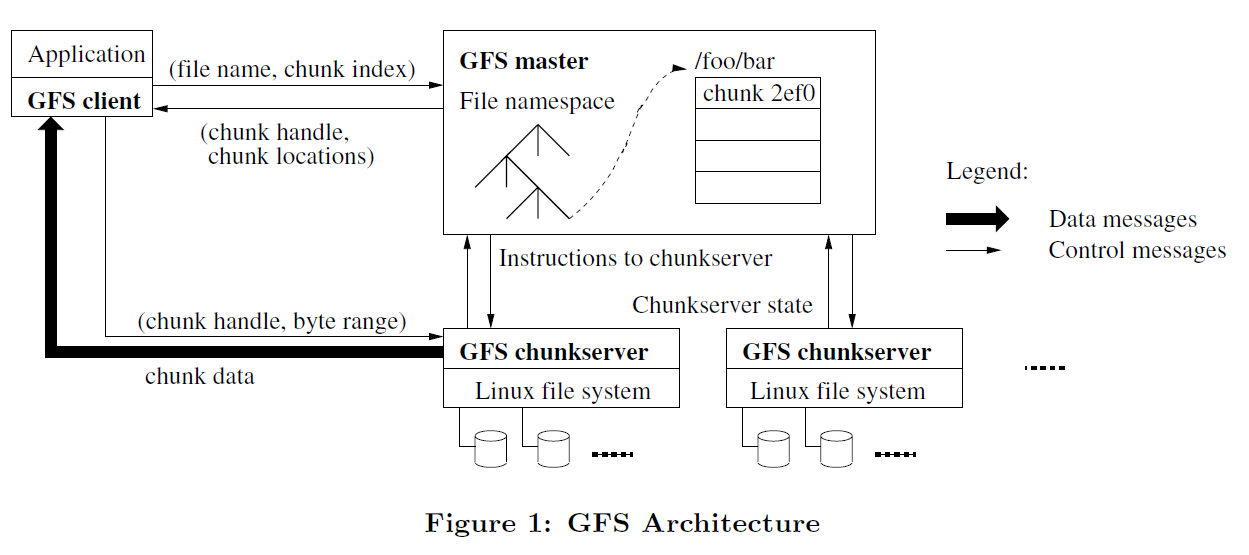
一个 GFS 集群由一个 master 节点和多个 chunkserver 组成,同时被多个客户端访问,流程如下图所示。
-
GFS 存储的文件被划分成固定大小的 chunk块,在创建文件时,master 会给每个 chunk 分配一个不变的,全局唯一的64位的标识。chunkserver 将 chunk 以 linux 文件的形式保存到本地磁盘上,根据客户端指定的chunk 标识和字节范围来读。可靠性保证上,chunk 块会复制到多台机器上(默认三备份)。
-
master 节点维持所有文件系统的元数据,这些元数据包括命名空间、访问控制信息、文件到 chunk块的映射信息以及chunk块的具体位置信息。master 节点同时还控制着系统范围内的活动,例如 chunk租用、孤儿 chunk 回收,以及 chunk块之间的迁移。master 节点和 chunkserver 之间通过心跳信息交流并更新服务器的状态信息。
-
GFS 的客户端用户程序实现了 GFS 的 API ,封装了与 master 节点和 chunkserver 节点之间的网络通讯细节。客户端和 master 节点仅交流元数据,数据块的传送则是直接访问 chunkserver。
-
客户端和 chunkserver 并不缓存文件数据。该文件系统面向于以流式方式读取大尺寸文件的系统,不想关系型数据库系统之间存在的某些特定数据访问次数不协调造成的"数据热点问题"。
- 客户端会缓存特定的元数据信息,可以减缓 master 节点的高负载,降低 master 节点出现单点故障的可能性。
- chunkserver 也不缓存数据,仅通过操作系统的本机文件系统来缓存经常访问的数据。
以下分别总结了论文中 GFS 的不同部分来阐述了其设计细节。
2.4 Single Master
单一 master 节点能简化实现,可精准的定位 chunk 所在位置并对 chunk 进行复制决策。单一 master 节点易成为全局瓶颈,必须减少对 master 节点的读写操作,因此客户端仅通过 master 节点读取元数据,读写文件时访问 chunkserver,并且客户端会缓存一定时间段内的元数据信息,避免额外的网络开销。
客户端的读取流程如下:
- 客户端指定文件名和文件的范围,根据固定的 chunk 块大小,转换为 chunk 索引,将文件名和 chunk 索引发送给 master 节点;
- master 节点将 chunk 标志和副本的位置信息发回给客户端后,客户端会将其信息缓存;
- 客户端根据得到的信息,选择距离自己最近的 chunkserver,发送 {chunk 标识,字节范围} 的读取请求。
另外,客户端可一次请求多个 chunk 信息,降低多次请求 mater 节点的网络 I/O 。
2.5 ChunkSize
将 chunk 文件的大小设置为 64 MB,有如下优缺点考量:
优点:
- 减少客户端和 master 节点的通信次数。这样可以使得 chunk 块的数量降低,降低了工作负载。
- 客户端可对一个 chunk 进行多次操作,可保持 TCP 长连接来降低网络负载。
- 减少了 master 节点需要保存的元数据信息数量,使元数据保存在 master 节点的内存中,减少磁盘 I/O 的次数或者不用磁盘 I/O。
缺点:
-
将小文件填充满 64MB,易造成块内碎片问题,浪费存储空间。
-
对多个小文件多次访问时,易造成热点问题。但 GFS 的主要是针对多个 chunk 的大文件进行连续读取,热点问题不是主要的。
热点问题,可通过增加 chunk 的副本数量、允许客户端从其它客户端读数据等方式解决。
2.6 Metadata
master 节点存储如下元数据信息:文件和 chunk 的命名空间、文件到 chunk 的映射关系,chunk 副本的具体位置。
- 为保证可靠性,master 节点会将 文件和 chunk 的命名空间、文件到 chunk 的映射关系 这部分通过日志的信息落盘持久化,同时这部分信息也会通过日志的信息复制到备用 master 节点上。
- master 节点不持久保存 chunk 副本的具体位置,通过网络通讯轮询 chunkserver 中所存储的 chunk 信息。
这部分论文通过内存型数据结构、chunk位置信息和日志复制三部分来阐述了元数据信息的管理:
2.6.1 In-Memory Data Structures
元数据信息存储在内存中,master 节点在后台定期的扫描全部状态信息,同时用于实现 chunk 垃圾收集、chunkserver失效时拷贝副本、迁移 chunk 以实现负载均衡、磁盘状态统计等功能。
因此,内存大小可能存在潜在问题,master 节点的内存大小制约着 chunk 数量及系统的承载能力。在当时(2003)年,内存还是稀缺资源,作者在文中指出额外增加内存使得元数据全部位于内存中,能增加系统的简洁性、可靠性、高性能和灵活性。
2.6.2 Chunk Locations
由于 chunkserver 存在加入集群、离开集群、更名、失效、重启等操作,因此将 chunk 的位置信息持久保存在 master 节点上不太合适的。因此 GFS 将定期轮询的方式更新 chunk 的信息,并通过周期性的心跳信息监控 chunkserver 状态。
这种设计决策是基于以下直觉:只有chunkserver 才能最终确定 chunk 是否在其硬盘上,不能由 master 节点来决定。
2.6.3 Operation Log
操作日志被用于持久化存储记录、判断同步操作顺序的时间基线,对 GFS 来说很重要。日志的关键设计决策如下:
- 恢复时,通过 replay log 来时系统恢复到最近状态。
- 日志中设置了 checkpoint 来减少日志的文件大小,且将 checkpoint 以压缩 B- 树的形式组织。
- master 节点设置独立线程来创建新的日志和 checkpoint 文件,因此创建 checkpoint 过程中不会阻塞当前修改操作。
- 旧的 checkpoint 文件仍被保留,以应对灾难性的故障。
2.7 Consistency Model
- 一致:chunk 副本全部更新完毕,表现为无论从哪个副本读,读到的数据都一样。
- 已定义(包含了一致):所有客户端都能读到已写的数据
- 一致,未定义:所有的客户端看到同样的数据,但是无法读到任何一次写入操作所写入的数据。
- 未定义(包含了不一致):不同客户端在不同时间看到了不同数据
3. System Interactions
系统的交互的设计核心就是最小化所有操作和 master 节点之间的交互,保证 master 节点不会成为瓶颈,本节介绍了客户端、master 节点和 chunkserver 之间的交互操作。
3.1 Leases and Mutation Order
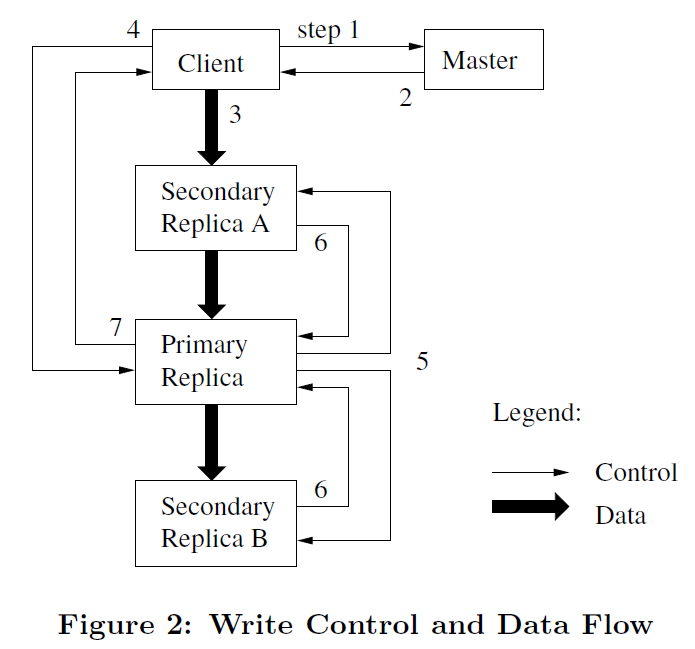
变更指的是会改变 chunk 内容和元数据的相关操作,发生变更后,其会在所有 chunk 副本上执行相应操作。为了保证多副本之间的一致性,master 节点会为 chunk 的一个副本建立租约,获得租约的副本为主 chunk,主 chunk 首先会对 chunk 的变更操作进行序列化,其余副本 chunk 会依据这个序列进行修改操作。因此,修改操作首先由 master 节点选择租约,并由主 chunk的序列号决定变更,这样最小化 master 节点管理的负担。
建立租约的流程如下:
-
客户端向 master 节点询问哪个 chunkserver 持有租约,以及所有副本的位置。如果当前没有 chunkserver 持有租约,则有 master 节点在 chunk 副本中选择并建立一个租约。
-
master 节点将主 chunk 的标识以及其它副本的位置返回给客户端。客户端会将这部分内容缓存以减少每次询问 master 节点的开销,只有主 chunk 不可用或者其不再持有租约时,客户端才会和 master 节点联系。
-
客户端会将待写的数据发送到任一副本上,然后那个副本会将数据以 LRU 的方式保存在内存中并立马发送给其它副本。其中,发送的方式是以网络拓扑进行规划的,例如,“A<->B<->C” 的网络通路,客户端发送给 A 后,A 将其发送给 B ,B 又发送给 C,以数据流的形式在网络中进行传递。
这种数据同步方式,只需要客户端发送一份至任一副本即可,充分利用了不同副本所在机器的网络带宽,降低了客户端发生网络拥塞的可能性,增大了吞吐量。
-
当所有副本都确认收到数据后,客户端发送写请求到主 chunk,该请求标识了之前推送到所有副本的数据,主 chunk 接收到后会为所有的操作分配连续的序列号,该序列号保证了顺序操作(用于处理多客户端同时写),然后按照顺序执行操作,更新状态。
-
主 chunk 将这些序列请求传递到其它副本,其它副本也以同样顺序执行相同操作,并落盘。
-
其它副本回复主 chunk ,告知完成操作。如果出现任一副本出现错误,会将错误发送至主 chunk。
-
主 chunk 回复消息给客户端。如果失败,主 chunk 会返回失败消息给客户端,客户端会从步骤 3 开始重新执行。
如果客户端一次写入数据量过多,或者数据跨越了多个 chunk,客户端会将其分为多个写操作。
3.2 Data Flow
如 3.2 节所述的数据传输过程,GFS 分离了控制流和数据流,数据沿着一个一个基于网络拓扑的链式结构推送,有如下优势:
- 充分利用了每台机器的带宽,数据沿着 chunkserver 顺序链推送。
- 避免网络瓶颈和高延迟连接,每台机器在网络拓扑中选择一台还未接受到数据的、离自己最近的机器作为目标推送数据。距离的衡量标准为 IP 地址。
- 基于 TCP、管道式的方式来获得最小化延迟。
3.3 Atomic Record Appends
客户端指定写入数据后,GFS保证至少有一次原子的写入操作成功执行。
追加写时,同样和 3.1 中的过程一致,客户端会将追加写的数据写入到该文件的最后的一个 chunk 的所有副本,然后发送请求给主 chunk,主 chunk 会根据追加数据是否超过 chunksize,来做出追加写的决策。
如果追加写操作在任一副本失败了,客户端需要重新操作,重新进行追加写可能会导致不同副本包含不同的数据(重复包含一个记录的全部或部分数据)。GFS 并不保证所有 chunk 副本在字节级别上是完全一致的,其仅保证至少会被原子的写入一次。因此处理脏数据时,需要客户端可能需要根据序列号过滤掉某些 chunk 副本,或者由 master 来淘汰掉不一致的副本。
3.4 Snapshot
GFS 采用 copy-on-write 技术实现快照,快照的相关细节如下:
- master 节点收到快照请求后,首先取消请求快照的文件的所有 chunk 的租约,这保证了后续对这些 chunk 的写操作都必须和 master 重新建立租约。
- 取消租约后,master 节点间快照请求操作写日志后,master 节点创建的快照文件和原文件指向相同的 chunk地址。
- 建立快照后,如果对源文件或者快照进行修改操作时,此时会使得其在本地机器上创建一个新 chunk 文件,更改对应的数据信息,然后客户端的修改将在这个新 chunk 上进行。
4. Master Operation
master 节点管理着所有 chunk 的副本:其决定了 chunk 的存储位置,创建新 chunk 及 chunk 副本,协调各式各样的系统活动以保证 chunk 的复制,对所有的 chunkserver 记下来负载均衡,以及回收存储空间等。本节论文分别讨论了以上主题。
4.1 Namespace Management and Locking
master 节点上的操作往往需要耗费较长时间,为了增加操作间的并行性,本节规定了在 GFS 文件目录树的锁机制。
- 在文件访问时,沿着路径按顺序对目录加读锁,对文件加写锁。
- 对于同一层次上的文件,按照文件名的字典序加锁
4.2 Replica Placement
GFS 副本位置的选择策略是最大化数据可靠性和网络带宽利用率,由如下具体实践:
- 需要在跨机架或不同数据中心的情况下建立副本,实现不同等级的高可用。
- 需要有效利用多个机架的整合带宽。
4.3 Creation, Re-replication, Rebalancing
master 创建一个 chunk 时,其需要选择初始空副本的位置,其会考虑以下因素:
- chunkserver 的磁盘利用率
- chunkserver 的最近创建次数(最近如果发生了多次创建,则可能该 chunkserver 随之会有大量写入操作,其网络负载高)
- 在多机架间复制副本
当某一 chunk 的有效副本数量低于设定值时,master 节点会发起复制操作。在复制操作时,有不同的优先级:
- 会根据 chunk 现有数量和设定值的差别来赋予复制操作的优先级。
- 优先复制活跃的文件,而不是最近被删除的文件的 chunk。
此外, master 会周期性的对副本进行重新负载均衡,检查副本的分布情况,处理新 chunkserver 和 chunkserver 过载的情况,平衡系统整体的磁盘利用率。
4.4 Garbage Collection
在文件删除时,GFS 不会立刻回收物理空间,其在文件和 chunk 级别进行采用惰性回收策略。该方法能使系统更简单可靠。
GFS 删除文件的机制如下:
- 先用日志记录删除操作
- 将文件名后加上删除实践戳的后缀,并隐藏该文件的可见性
- master 定期扫描,删除一个时间间隔前的文件,实现真正的删除。(首先删除元数据,后通知 chunkserver 删除)
- 在被 master 扫描删除前, 其仍可以特殊读取,也可以实现取消删除操作
该惰性回收策略策略的优势如下:
- 简单可靠
- 将垃圾回收策略转为批量执行,可以在服务器空闲时完成,分散了开销
- 为意外删除后的恢复操作提供了安全保障
但缺点是不能有效的利用存储空间。
4.5 Stale Replica Detection
为了分辨当前副本和过期副本,master 节点保存了每个 chunk 的版本号。版本号的机制如下所述:
- 当 master 节点和 chunk 建立租约时,会增加 chunk 的版本号,随后 master 会将该版本号落盘持久化存储
- 每当 master 和 chunkserver 交换数据时,会检查每个 chunk 的版本信息,如果发现某 chunk 的版本号比 master 存储的低,则说明该 chunk 为过期副本;如果某 chunk 的版本号比 master 存储的高,则 master 会重新建立租约。
- master 给客户端的消息中,附带了 chunk 的版本号,以保证客户端和 chunkserver 通信时能进行版本号检查,确定访问的的数据版本是最新的。
5. Fault Tolerance and Diagnosis
GFS 需要处理组件失效的问题,在高可用性和出错诊断下做出了以下设计。
5.1 High Availability
- 快速恢复:重启后可通过 checkpoint 机制快速恢复
- chunk 复制:设定了副本 chunk 用于容错
- master 节点复制:设置影子 master 服务器,同步 master 节点的操作日志和 checkpoint。
5.2 Data Integrity
每个 chunkserver 维护 checksum 来校验副本的完整性。
- 将 chunk 分为 64 KB 的块,每个块都对应着 32 位的 checksum。
- chunkserver 在将数据发送至客户端或其它 chunkserver 之前,会对数据块中的 cecksum 进行对比,如果不一致则会返回错误信息,并通知 master 服务器进行错误处理。
- 在 chunkserver 空闲时,其会扫描不活动的 chunk,并进行校验,如果出现数据损坏的样本,则同时 master 为此建立新的副本。
Summary
GFS 针对大文件顺序读写或追加写操作的工作负载,将文件的管理和存储分别分离到 master 节点和 chunkserver 上,实现了多副本的高效管理,在存储方面,将文件分成 chunk 存储与多个 chunkserver 上,充分利用了 sharding 所带来的并行吞吐量,另外,其通过精巧的设计(租约机制,垃圾回收,副本复制和平衡)保证了高可用性和容错性。但仍存在以下问题:单点故障,小尺寸文件效率问题、一致性约束较为宽松。
Reference
-
https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf “The Google File System” ↩︎